Yiff Toolkit
Bevezetés
A yiff_toolkit egy átfogó eszközkészlet, amelyet a furry művészet területén való kreatív folyamatod fejlesztésére terveztek. A művészi stílusok finomításától az egyedi karakterek generálásáig a Yiff Toolkit különféle eszközöket biztosít, hogy segítsen neked élvezni a folyamatot.
Alszekciók
- LoRA Betanítási Útmutató
- A LoRA Betanítási Útmutató bemutatja az Alacsony Rangú Adaptációt (LoRA), egy technikát a nagy nyelvi és diffúziós modellek hatékony finomhangolására kis, betanítható alacsony rangú mátrixok bevezetésével az összes modellparaméter módosítása helyett. Ez a megközelítés az eredeti modell súlyait változatlanul hagyja, és két további mátrixot illeszt be minden rétegbe a szükséges módosítások megtanulásához. A LoRA könnyűsúlyú, így több adaptáció betanítása is megvalósítható nagy tárolási követelmények nélkül. Az útmutató összehasonlítja a LoRA-t a LyCORIS-szal, egy fejlett kiterjesztéssel, amely több irányítást és rugalmasságot kínál, és bemutatja a LoKr-t, amely Kronecker-szorzatokat használ a mátrix felbontásához, javítva a memóriahatékonyságot és az adaptációs folyamat irányítását.
- A ComfyUI Biblia
- Átfogó útmutató a ComfyUI használatához, az alapvető node-alapú munkafolyamatoktól a fejlett AI képgenerálási technikákig.
- Adathalmaz Eszközök
- Egy “kis” gyűjtemény Python és PowerShell szkriptekből, amelyeket az adathalmaz kurátorok hasznosnak találhatnak.
Adatkészlet Eszközök
Az összes hasznos Python és Rust szkriptet feltöltöttem a
/dataset_tools oldalra. A legtöbb önmagáért beszél már csak a fájlnév alapján is, de szinte mindegyik tartalmaz AI által generált leírást. Ha használni szeretnéd őket, szerkesztened kell a training_dir mappához vezető útvonalat. A változó neve általában path vagy directory, és így néz ki:
def main():
path = 'C:\\Users\\kade\\Desktop\\training_dir_staging'
Ne félj a Python szkriptek szerkesztésétől, az igazi kígyóval ellentétben ezek nem harapnak! Legrosszabb esetben csak törlik a fájljaidat!
Van még ez a cucc is.
Adatkészlet Előkészítése
Mielőtt elkezdenéd az adatkészleted gyűjtését, el kell döntened, mit szeretnél megtanítani a modellnek, lehet ez egy karakter, egy stílus vagy egy új koncepció.
Most képzeljük el, hogy wickerbeast-eket szeretnél tanítani a modellednek, hogy minden este generálhasd a VRChat avatarodat.
A training_dir Könyvtár Létrehozása
Mielőtt elkezdenénk, szükségünk van egy könyvtárra, ahol rendszerezzük az adatkészleteinket. Nyiss meg egy terminált a Win + R megnyomásával és a pwsh beírásával. A git és a huggingface segítségével fogjuk verziókezelni a dolgainkat. A rövidség kedvéért nem adok mindkettőről részletes útmutatót, de szerencsére a 🤗 írt egyet. Miután elkészítetted az új adatkészletedet a HF-en, klónozzuk le. Győződj meg róla, hogy az első sorban lecseréled a user-t a HF felhasználónevedre!
git clone git@hf.co:/datasets/user/training_dir C:\training_dir
cd C:\training_dir
git branch wickerbeast
git checkout wickerbeast
Folytassuk néhány wickerbeast adat letöltésével, de ne zárd be még a terminál ablakot. Ehhez jól fogjuk használni a furry booru e621.net oldalt. Két jó módszer van az adatok letöltésére erről az oldalról a metaadatokkal együtt, először a leggyorsabbal kezdem, majd elmagyarázom, hogyan böngészhetsz szelektíven az oldalon és szerezheted meg egyesével a neked tetsző képeket.
Grabber
A Grabber megkönnyíti az életed, amikor gyorsan szeretnél adatkészleteket összeállítani képtáblákról.

A Letöltés fülön az Add gombra kattintva hozzáadhatsz egy csoportot, amely letöltésre kerül. A Tags mezőbe írhatod be a keresési paramétereket, ahogy az e621.net oldalon tennéd, tehát például a wickerbeast solo -comic -meme -animated order:score karakterlánc egyedülálló wickerbeast képeket keres, kihagyva a képregényeket, mémeket és animált bejegyzéseket, pontszám szerinti csökkenő sorrendben. SDXL LoRA-k tanításához általában nem lesz szükséged 50 képnél többre, de állítsd be a solo csoportot 40-re, és adj hozzá egy új csoportot -solo helyett solo-val, és állítsd be a Képek Limitjét 10-re, hogy néhány olyan képet is tartalmazzon, amelyeken más karakterek is szerepelnek. Ez segít a modellnek sokkal jobban tanulni!
Az e621 esetében engedélyezned kell a Separate log files opciót is, ez automatikusan letölti a metaadatokat a képekkel együtt.

A Pony esetében a Szövegfájl tartalmát így állítottam be: rating_%rating%, %all:separator=^, %, más modelleknél lehet, hogy a rating_%rating%-et csak %rating%-re szeretnéd cserélni. A SeaArt/CompassMix esetében például a %all:separator=^, %, %rating%-et használom.
Be kell állítanod azt a Mappát is, ahova a képek letöltésre kerülnek. Használjuk a C:\training_dir\1_wickerbeast mappát mindkét csoporthoz.
Most készen állsz arra, hogy jobb klikkel rákattints minden csoportra és letöltsd a képeket.
Az e6ai.net hozzáadása a Grabberhez
Kattints a lépések felfedéséhez
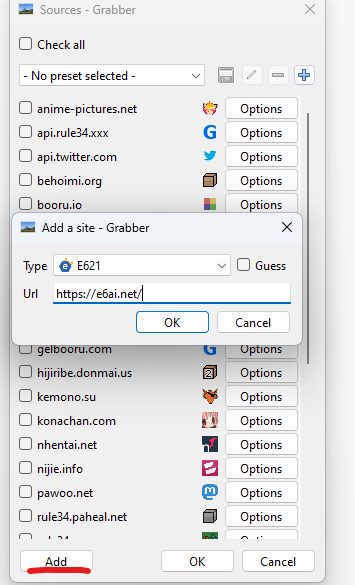
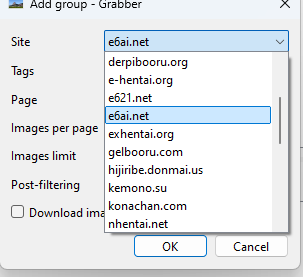
Manuális Módszer
Ez a módszer egy böngésző kiegészítőt igényel, mint például a ViolentMonkey és ezt a UserScriptet.
Ez egy linket helyez el a JSON-hoz a letöltés gomb mellett az e621.net és e6ai.net oldalakon, és használhatod
ezt a Python szkriptet a feliratfájlokká való konvertáláshoz. A rating_ előtagot használja a safe/questionable/explicit előtt, mert… igen, kitaláltad, Pony! Lehetővé teszi azt is, hogy figyelmen kívül hagyd az ignored_tags-be hozzáadott címkéket az r"\btag\b", szintaxis használatával, csak cseréld ki a tag-et arra a címkére, amit ki szeretnél hagyni.
Automatikus Címkézők
JTP2
Használhatod a címkéző szkriptemet, csak tedd be a 2. verzió mappájába és hívd meg egy képekkel teli könyvtáron, hogy mindent felcímkézzen.
Szükséged lesz a torch, safetensors, Pillow és timm csomagokra is, hogy ez a dolog működjön!