イフツールキット
はじめに
yiff_toolkitは、ファーリーアートの分野であなたの創作プロセスを強化するために設計された包括的なツール群です。アーティストのスタイルの洗練から独自のキャラクター生成まで、イフツールキットはあなたの創作活動をサポートする様々なツールを提供します。
サブセクション
- LoRA トレーニングガイド
- LoRAトレーニングガイドでは、大規模な言語モデルや拡散モデルを効率的に微調整するための手法であるLow-Rank Adaptation(LoRA)について説明します。この手法は、すべてのモデルパラメータを変更する代わりに、小さな訓練可能な低ランク行列を導入します。このアプローチでは、元のモデルの重みを固定したまま、各層に2つの追加行列を挿入して必要な調整を学習します。LoRAは軽量で、大容量のストレージを必要とせずに複数の適応を訓練することが可能です。このガイドでは、より多くの制御と柔軟性を提供する高度な拡張であるLyCORISとの比較も行い、行列分解にクロネッカー積を使用して、メモリ効率と適応プロセスの制御を向上させるLoKrについても紹介します。
- 自作LoRA
- LoRA(Low-Rank Adaptation)は、特定のスタイルやコンセプトでモデルを微調整するための技術です。ここでは私が作成したLoRAを紹介します。
- ComfyUIバイブル
- ComfyUIの使用方法を包括的に解説するガイド。基本的なノードワークフローから高度なAI画像生成テクニックまでをカバー。
- データセットツール
- データセットキュレーターにとって便利なPythonとPowerShellスクリプトの「小さな」コレクション。
データセットツール
私が使用している便利なPythonとRustのスクリプトをすべて
/dataset_toolsにアップロードしました。ファイル名を見るだけでほとんど説明は不要ですが、ほぼすべてのスクリプトにAIが生成した説明が含まれています。使用する場合は、training_dirフォルダへのパスを編集する必要があります。変数はpathまたはdirectoryという名前で、以下のような形式になっています:
def main():
path = 'C:\\Users\\kade\\Desktop\\training_dir_staging'
Pythonスクリプトの編集を恐れないでください。本物のヘビと違って、これらは噛みつきません!最悪の場合でも、ファイルを削除するだけです!
また、これも用意しています。
データセット準備
データセットの収集を始める前に、モデルに何を教えたいのかを決める必要があります。それはキャラクター、スタイル、または新しいコンセプトかもしれません。
ここでは例として、毎晩VRChatアバターを生成できるように、モデルに_wickerbeast_を教えたい場合を想定してみましょう。
training_dirディレクトリの作成
始める前に、データセットを整理するためのディレクトリが必要です。Win + Rを押してpwshと入力してターミナルを開きます。また、gitとhuggingfaceを使用してバージョン管理を行います。簡潔にするため、両方のチュートリアルは省略しますが、幸いにも🤗がチュートリアルを書いています。HFに新しいデータセットを作成したら、クローンしましょう。最初の行のuserをあなたのHFユーザー名に変更することを忘れないでください!
git clone git@hf.co:/datasets/user/training_dir C:\training_dir
cd C:\training_dir
git branch wickerbeast
git checkout wickerbeast
_wickerbeast_のデータのダウンロードに進みましょう。ターミナルウィンドウはまだ閉じないでください。このために、ファーリーボールのe621.netを活用します。メタデータを保持したままこのサイトからデータをダウンロードする方法は2つあります。最も速い方法から説明し、その後、サイトを選択的に閲覧して1枚ずつ好きな画像を取得する方法を説明します。
Grabber
Grabberは、画像掲示板からデータセットを素早くコンパイルする際の作業を簡単にします。

ダウンロードタブのAddボタンをクリックすると、ダウンロードするgroupを追加できます。Tagsにはe621.netで使用するような検索パラメータを入力できます。例えば、wickerbeast solo -comic -meme -animated order:scoreという文字列は、コミック、ミーム、アニメーション投稿を除外した単独のwickerbeast画像をスコア順に検索します。SDXL LoRAのトレーニングには通常50枚以上の画像は必要ありませんが、soloグループを40に設定し、soloの代わりに-soloを使用して新しいグループを追加し、Image Limitを10に設定して、他のキャラクターを含む画像も含めるようにすると良いでしょう。これによりモデルの学習効果が大幅に向上します!
また、e621用にSeparate log filesを有効にすると、画像と一緒にメタデータが自動的にダウンロードされます。

Pony用に、テキストファイルの内容をrating_%rating%, %all:separator=^, %のように設定しています。他のモデルでは、rating_%rating%を単に%rating%に置き換えたい場合があります。例えば、SeaArt/CompassMixでは%all:separator=^, %, %rating%を使用しています。
また、画像がダウンロードされるFolderを設定する必要があります。両方のグループにC:\training_dir\1_wickerbeastを使用しましょう。
これで各グループを右クリックして画像をダウンロードする準備が整いました。
GrabberにE6ai.netを追加する
手順を表示するにはクリックしてください
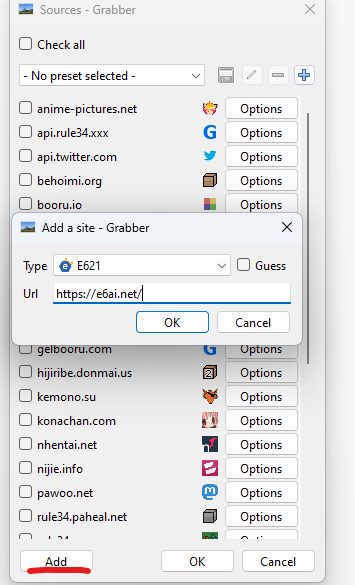
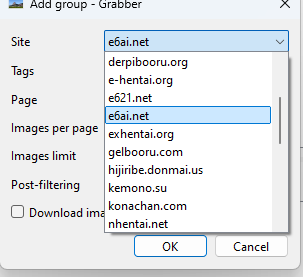
手動方法
この方法にはViolentMonkeyのようなブラウザ拡張機能と このUserScriptが必要です。
これによりe621.netとe6ai.netのダウンロードボタンの横にJSONへのリンクが追加され、
このPythonスクリプトを使用してキャプションファイルに変換できます。safe/questionable/explicitの前にrating_プレフィックスを使用しているのは…そう、Ponyのためです!また、r"\btag\b",構文を使用してignored_tagsに追加したタグを無視することもできます。tagをスキップしたいタグに置き換えるだけです。
自動タグ付けツール
JTP2
私のタガースクリプトを使用できます。第2バージョンのフォルダに入れて、画像が入ったディレクトリに対して実行するだけで、すべてにタグが付けられます。
このツールを動作させるには、torch、safetensors、Pillow、timmをインストールする必要があります!
ソースコードを表示するにはクリックしてください。
import os
import json
from PIL import Image
import safetensors.torch
import timm
from timm.models import VisionTransformer
import torch
from torchvision.transforms import transforms
from torchvision.transforms import InterpolationMode
import torchvision.transforms.functional as TF
import argparse
torch.set_grad_enabled(False)
class Fit(torch.nn.Module):
def __init__(self, bounds: tuple[int, int] | int, interpolation=InterpolationMode.LANCZOS, grow: bool = True, pad: float | None = None):
super().__init__()
self.bounds = (bounds, bounds) if isinstance(bounds, int) else bounds
self.interpolation = interpolation
self.grow = grow
self.pad = pad
def forward(self, img: Image) -> Image:
wimg, himg = img.size
hbound, wbound = self.bounds
hscale = hbound / himg
wscale = wbound / wimg
if not self.grow:
hscale = min(hscale, 1.0)
wscale = min(wscale, 1.0)
scale = min(hscale, wscale)
if scale == 1.0:
return img
hnew = min(round(himg * scale), hbound)
wnew = min(round(wimg * scale), wbound)
img = TF.resize(img, (hnew, wnew), self.interpolation)
if self.pad is None:
return img
hpad = hbound - hnew
wpad = wbound - wnew
tpad = hpad // 2
bpad = hpad - tpad
lpad = wpad // 2
rpad = wpad - lpad
return TF.pad(img, (lpad, tpad, rpad, bpad), self.pad)
def __repr__(self) -> str:
return f"{self.__class__.__name__}(bounds={self.bounds}, interpolation={self.interpolation.value}, grow={self.grow}, pad={self.pad})"
class CompositeAlpha(torch.nn.Module):
def __init__(self, background: tuple[float, float, float] | float):
super().__init__()
self.background = (background, background, background) if isinstance(background, float) else background
self.background = torch.tensor(self.background).unsqueeze(1).unsqueeze(2)
def forward(self, img: torch.Tensor) -> torch.Tensor:
if img.shape[-3] == 3:
return img
alpha = img[..., 3, None, :, :]
img[..., :3, :, :] *= alpha
background = self.background.expand(-1, img.shape[-2], img.shape[-1])
if background.ndim == 1:
background = background[:, None, None]
elif background.ndim == 2:
background = background[None, :, :]
img[..., :3, :, :] += (1.0 - alpha) * background
return img[..., :3, :, :]
def __repr__(self) -> str:
return f"{self.__class__.__name__}(background={self.background})"
transform = transforms.Compose([
Fit((384, 384)),
transforms.ToTensor(),
CompositeAlpha(0.5),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], inplace=True),
transforms.CenterCrop((384, 384)),
])
model = timm.create_model("vit_so400m_patch14_siglip_384.webli", pretrained=False, num_classes=9083) # type: VisionTransformer
class GatedHead(torch.nn.Module):
def __init__(self, num_features: int, num_classes: int):
super().__init__()
self.num_classes = num_classes
self.linear = torch.nn.Linear(num_features, num_classes * 2)
self.act = torch.nn.Sigmoid()
self.gate = torch.nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.linear(x)
x = self.act(x[:, :self.num_classes]) * self.gate(x[:, self.num_classes:])
return x
model.head = GatedHead(min(model.head.weight.shape), 9083)
safetensors.torch.load_model(model, "JTP_PILOT2-e3-vit_so400m_patch14_siglip_384.safetensors")
if torch.cuda.is_available():
model.cuda()
if torch.cuda.get_device_capability()[0] >= 7: # tensor cores
model.to(dtype=torch.float16, memory_format=torch.channels_last)
model.eval()
with open("tags.json", "r") as file:
tags = json.load(file) # type: dict
allowed_tags = list(tags.keys())
for idx, tag in enumerate(allowed_tags):
allowed_tags[idx] = tag.replace("_", " ")
sorted_tag_score = {}
def run_classifier(image, threshold):
global sorted_tag_score
img = image.convert('RGBA')
tensor = transform(img).unsqueeze(0)
if torch.cuda.is_available():
tensor = tensor.cuda()
if torch.cuda.get_device_capability()[0] >= 7: # tensor cores
tensor = tensor.to(dtype=torch.float16, memory_format=torch.channels_last)
with torch.no_grad():
probits = model(tensor)[0].cpu()
values, indices = probits.topk(250)
tag_score = dict()
for i in range(indices.size(0)):
tag_score[allowed_tags[indices[i]]] = values[i].item()
sorted_tag_score = dict(sorted(tag_score.items(), key=lambda item: item[1], reverse=True))
return create_tags(threshold)
def create_tags(threshold):
global sorted_tag_score
filtered_tag_score = {key: value for key, value in sorted_tag_score.items() if value > threshold}
text_no_impl = ", ".join(filtered_tag_score.keys())
return text_no_impl, filtered_tag_score
def process_directory(directory, threshold):
results = {}
for root, _, files in os.walk(directory):
for file in files:
if file.lower().endswith(('.jpg', '.jpeg', '.png')):
image_path = os.path.join(root, file)
image = Image.open(image_path)
tags, _ = run_classifier(image, threshold)
results[image_path] = tags
# Save tags to a text file with the same name as the image
text_file_path = os.path.splitext(image_path)[0] + ".txt"
with open(text_file_path, "w") as text_file:
text_file.write(tags)
return results
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Run inference on a directory of images.")
parser.add_argument("directory", type=str, help="Target directory containing images.")
parser.add_argument("--threshold", type=float, default=0.2, help="Threshold for tag filtering.")
args = parser.parse_args()
results = process_directory(args.directory, args.threshold)
for image_path, tags in results.items():
print(f"{image_path}: {tags}")
eva02-vit-large-448-8046
このツールを使用するには、他の依存関係を除いて、torchのみをインストールする必要があります。
pip install timm
タガーの推論スクリプトにはフォルダを入力する必要があることに注意してください。警告として、WebP画像をPNGに変換し、タグを無視している他のものもあります。これを読んで必要な変更を加えることをお勧めします。
スクリプトへのリンクAutoCaptioners
これらのツールに頼るのはまだ早いかもしれませんが、新しい世代のものはすでにかなりの印象を与えています!それでも、これらのツールを使用する際には色、方向、そして各キャラクターの種類に注意してください!
Joy-Caption
git clone https://huggingface.co/spaces/fancyfeast
このツールを使用するには、meta-llama/Meta-Llama-3.1-8Bにアクセスする必要があります。
Tag Normalization with e6db
これツールを使用して、キャプションファイル内の暗示的なタグをフィルタリングすることができます。これを手動で行うことをお勧めします。
git clone https://huggingface.co/datasets/Gaeros/e6db
そして、このようにデータセットに対してそのまま実行することができます:
python ./normalize_tags.py /training_dir
私はgitまたは他の形式のバージョン管理を使用することをお勧めします。これらのツールを使用する際に行われた変更を比較するには、次のコマンドを使用できます:
git diff --word-diff-regex='[^,]+' --patience
現在のコミットと前のコミットの間の変更を比較するには、次のコマンドを使用できます:
git diff HEAD^ HEAD --word-diff-regex='[^,]+' --patience
Embeddings for 1.5 and SDXL
Stable Diffusionの埋め込みは、入力データ(画像やテキストなど)の高次元表現であり、その本質的な特徴と関係を捉えます。これらの埋め込みは拡散プロセスをガイドするために使用され、モデルが入力で指定された特性を生成するのに役立ちます。
/embeddingsフォルダには、SD 1.5用に収集したものを多数含むものがあります。後でこれツールを使用してSDXLに変換しました。
SDXL Furry Bible
ResAdapter
ResAdapter [Paper]は、モデルがトレーニングされた解像度の外にある画像を生成する能力を向上させます。これは何を意味するのでしょうか?それは、1024x1024よりも高い解像度の画像を生成できることを意味します。これは紙の上では素晴らしいことのように思えますが、実際にはマイルジョークになるかもしれません。これはまた、生成の一貫性を向上させるのにも役立ちます。
ただし、これをオンにしておくと、結果を比較するのが難しくなることに注意してください。時には、これがない方が良いこともあります。特に、Ponyのようなモデルでは、このモデルではv1のみを使用していますが、それでもうまく機能しています。また、ControlNet + IPAdapterと組み合わせて使用することも可能です。
CompassMix
新しいブロック、SeaArt Furryを基にしたLodestoneによるGANの魔法によって作成されたこのミックスは、元のモデルを改善することを試みましたが、成功しました!このミックスに対してLoRAをトレーニングするための推奨方法は、通常のミックスとして扱うことではなく、このミックスに対して直接LoRAをトレーニングすることです。私の実験([#1] [Dataset Reference], [#2] [Example Output])は、LoRAsがCompassに直接トレーニングされた場合、はるかに優れた結果をもたらすことを示しています。新しいcompass_optimizerをトレーニングスクリプトに追加することを忘れないでください。これは、一般化と全体的なトレーニングに役立ちます。これを設定するには、ここにあるものを使用することをお勧めします。これには、デフォルトのパラメータを使用して正規化を行うものが含まれています。また、縮小することを忘れないでください。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
SeaArt Furry
Pony Diffusion V6
Requirements
モデルをダウンロードして、画像を生成するために使用するものにロードします。
Positive Prompt Stuff
score_9, score_8_up, score_7_up, score_6_up, rating_explicit, source_furry,
私はあなたが_explicit_と_furry_を望んでいると仮定しました。また、レーティングをrating_safeまたはrating_questionableに設定し、ソースをsource_anime, source_cartoon, source_pony, source_rule34に設定することもできます。オプションで、これらを混ぜることもできます。それはあなたの生活です!score_9は興味深いタグです。モデルはその"artsy“知識をすべてここに入れているようです。あなたの生成物は_painterly_になるかもしれません。他の興味深いタグはscore_5_upです。これは品質に関する少しの知識を学んだようで、私はその最適な場所がネガティブプロンプトにあるか、ポジティブプロンプトにあるかを正確にはわかりませんでした。そのため、これを使用しませんが、score_4_upはアートに関するオートイスムススペクトラムにあるようで、使用しないことをお勧めしますが、あなたはどうするかを決めることができます!
Ponyと話すには3つの方法があります。タグのみを使用するか、タグは便利ですが、自然言語を使用してThe background is of full white marble towers in greek architecture style and a castle.と自然言語を最大限に使用することもできますが、最良の方法は両方を混ぜることです。これは実際に推奨されています。なぜなら、タグは定義上タグであり、使用する必要があるからです。また、トレーニング中にいくつかのランダムトークンによってソートされたコミュニティの努力によってソートされたここにあるように、いくつかのランダムトークンがソートされています。
他の素敵な言葉をボックスに入れることもできます。
detailed background, amazing_background, scenery porn
他の種類の背景には、
simple background, abstract background, spiral background, geometric background, heart background, gradient background, monotone background, pattern background, dotted background, stripped background, textured background, blurred background
simple backgroundの後に、背景の色を定義することもできます。
white background
キャラクターの描写には多くの異なるタイプを設定できます。
three-quarter view, full-length portrait, headshot portrait, bust portrait, half-length portrait, torso shot
それは、soloまたはduoまたはtrio, groupから始めて、最後に、興味深い状況でキャラクターを描写することをお勧めします。
How to Prompt Female Anthro Lions with PonyXL
Positive prompt:
anthro female african lion
Negative prompt:
mane
それだけです。

Thanks to OCPik4chu on Discord for the tip!